算法2026-06-24
CEO-Bench:让 AI 当 500 天 CEO,只有 Claude Opus 和 GPT-5.5 活下来,且都不赚钱
普林斯顿团队发布 CEO-Bench,模拟 AI Agent 运营一家创业公司 500 天:只有 Claude Opus 4.8 和 GPT-5.5 在结束时资产超过起始的 100 万美元,且两者都无法持续盈利。
算法2026-06-24
普林斯顿团队发布 CEO-Bench,模拟 AI Agent 运营一家创业公司 500 天:只有 Claude Opus 4.8 和 GPT-5.5 在结束时资产超过起始的 100 万美元,且两者都无法持续盈利。
算法2026-06-24
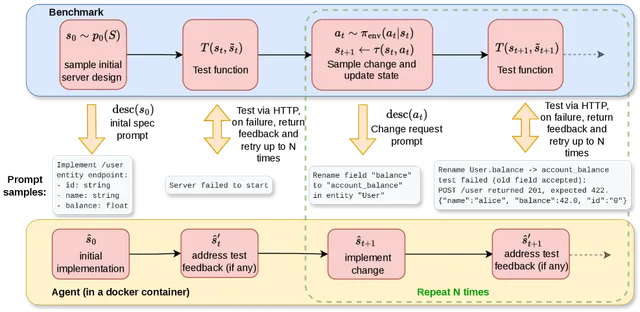
Amazon Science 发布 StaminaBench,在 100 轮连续修改任务中评测编程 Agent 的「耐力」:所有被测模型 5-6 轮内全部失败,但测试反馈可将存活轮数提升 12 倍,且 harness 质量差距可达 6 倍。
算法2026-06-24
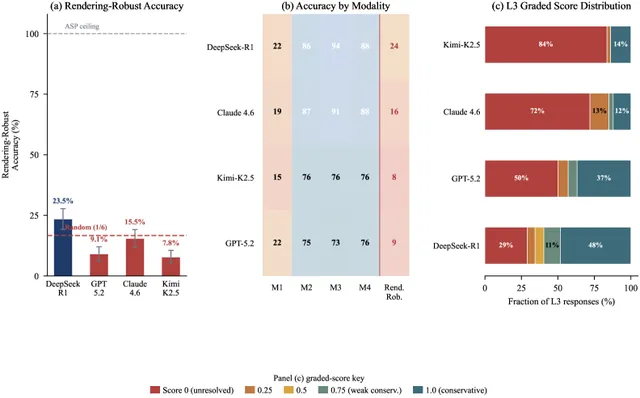
DeFAb 基准揭示残酷对比:基于规则的符号求解器 50 微秒内以 100% 准确率解决所有推理问题,最强前沿 LLM 最高仅 65%,渲染鲁棒评估暴跌至 23.5%。CoT 方差(36pp)超过任何模型间差距。
算法2026-06-24
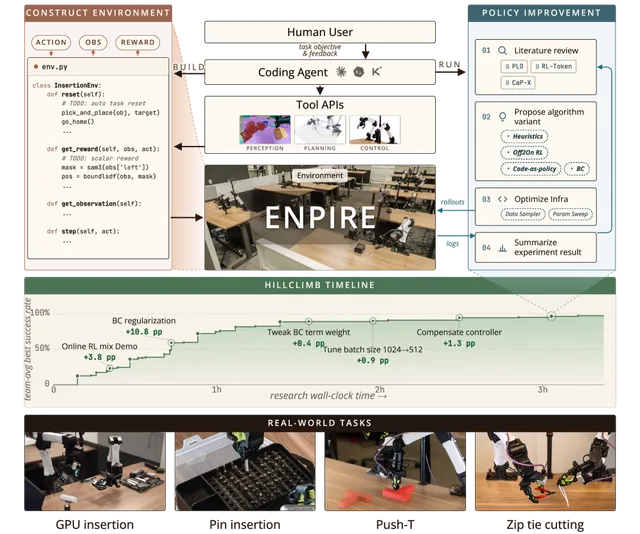
UC Berkeley、NVIDIA 等团队发布 ENPIRE 框架,让前沿编程 Agent 自主完成真实机器人的策略训练闭环——环境自动重置、策略迭代、物理执行、日志分析与改进——在插针盒、扎带、工具使用等灵巧操作任务上达到 99% 成功率,多机器人并行时进一步加速。
算法2026-06-24

韩国研究者发布 NRT-Bench,在模拟核电站控制室中测试 LLM Agent 操作员团队的安全韧性。多轮自适应攻击在 8.7%-12.1% 的会话中成功突破安全边界,更惊人的发现是:四个模型的失败几乎不重叠,同一套护栏对某些模型降低攻击成功率、对另一些模型反而提高。
算法2026-06-24
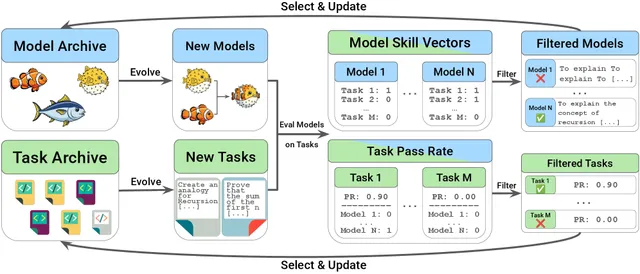
Sakana AI 在 ICLR 2026 提出 AC/DC 框架,通过模型合并与合成数据生成实现 LLM 种群的任务-能力协同进化,8 个小模型组成的集体可超越 72B 大模型,且无需针对任何 benchmark 优化。
算法2026-06-24

华中科技大学发布 Moebius,一个仅有 2 亿参数的图像 inpainting 模型,在多项指标上达到 10B 参数级模型的性能,为小模型在视觉生成领域树立了新标杆。
算法2026-06-24
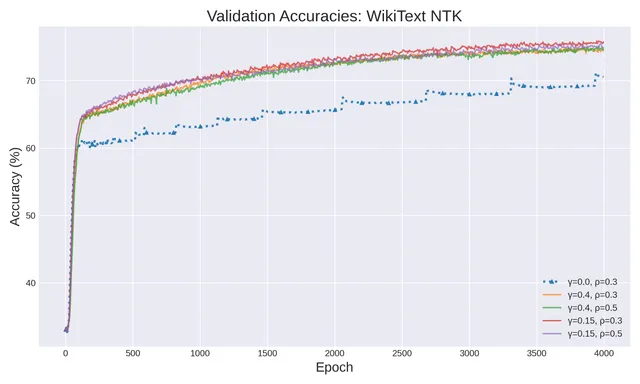
ICLR 2026 论文提出「噪声稳定性正则化」,在算法任务与语言建模上分别将训练加速 35% 和 75%,并催化 grokking 现象。方法源自布尔函数分析的理论创新。
算法2026-06-23

Artificial Analysis 发布 AA-Briefcase,一个全新的智能体知识工作评测基准,测试 LLM 在多周复杂项目中的规划与执行能力。由于基准刚发布、尚未被饱和,结果更具参考价值:Claude Fable 5 以 1587 Elo 居首,GLM-5.2 在 Agentic 能力上超越 GPT-5.5,开源模型价格优势显著。
算法2026-06-23
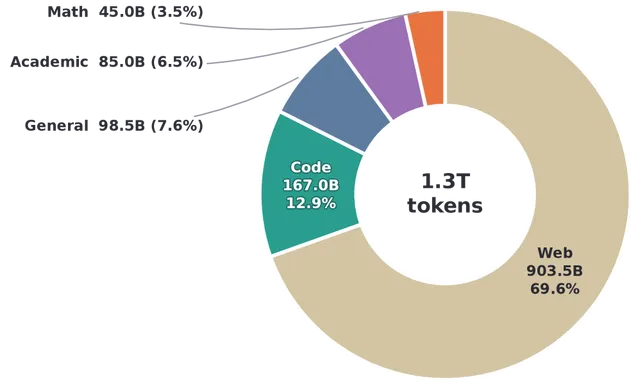
日本东北大学发布 Sumi,一个完全开源的 7B 统一扩散语言模型,在 1.5T token 上从零训练,是首个在参数规模和 token 预算上均达实用级别的 UDLM。
算法2026-06-21

Subquadratic 用动态稀疏注意力宣称将 LLM 推理成本从 O(n²) 降至亚二次方,Appen 独立评测数字惊人,但 Qwen 权重起点、封闭测试与社区质疑仍让「AI Theranos」标签挥之不去。
算法2026-06-20

Loft Orbital 的 YAM-9 卫星已在轨运行 Google Gemma 3 视觉语言模型,实现不依赖地面站的实时图像分析——AI 从云端向太空边缘延伸的里程碑。
算法2026-06-20
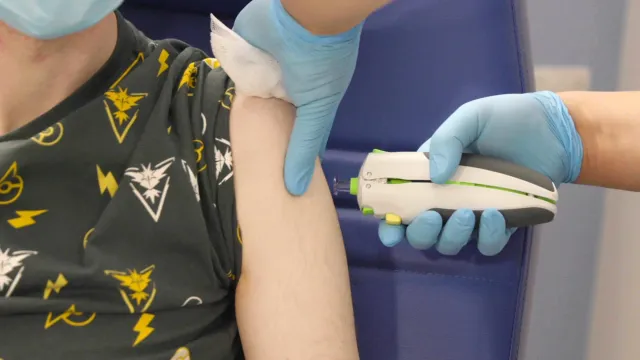
剑桥大学团队用 AI 从零设计出一种「超级抗原」,由此制成的通用冠状病毒疫苗通过首次人体临床试验。这是人类历史上第一次将 AI 完全设计的抗原注射到人体中并验证
算法2026-06-20
安全研究者发现一种名为 Agentjacking 的新型攻击,通过伪造 Sentry 错误通知即可劫持 Claude Code、Cursor 和 Codex,成
算法2026-06-20

Moonshot AI 发布 Kimi K2.7-Code,在 K2.6 基础上将 Kimi Code Bench v2 得分从 50.9 提升至 62.0(+
算法2026-06-20
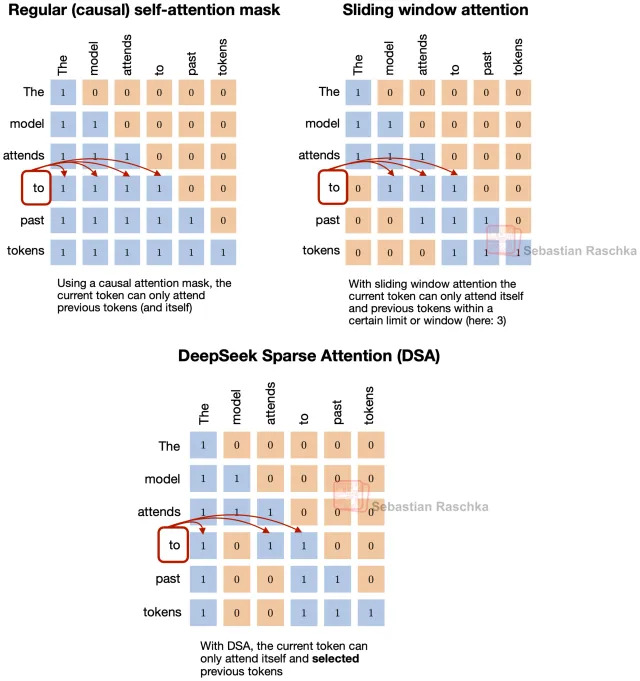
本文系统梳理 DeepSeek 稀疏注意力机制从 V3.2 到 FlashMemory-V4 的算法演进:DSA 的 Lightning Indexer、V4 的 CSA/HCA 混合架构,以及 2026 年 6 月最新提出的 Lookahead Sparse Attention 与 Neural Memory Indexer,揭示长上下文推理效率跃升背后的算法逻辑。
算法2026-06-20

KV Cache 已取代模型权重成为大模型推理的内存瓶颈。2026 年上半年,Google TurboQuant、Apple CommVQ 和华为 KVarN 三套压缩算法相继亮相,在 2–3 bit 精度下实现 6–8 倍压缩,本文从算法原理、基准对比和工程落地三个维度进行深度拆解。
算法2026-06-20

Google DeepMind 发布 DiffusionGemma,标志着扩散语言模型(dLLM)从学术论文走向生产级部署。本文深度剖析 dLLM 的技术原理、训练路线图、推理加速栈,以及它为何可能成为自回归模型之外最重要的架构替代方案。
算法2026-06-20

从 DeepSeek-R1 到 DAPO、Dr. GRPO,GRPO 算法如何让大模型在无人工标注的情况下学会推理,以及社区正在如何修补它的缺陷。
ENPIRE:编程 Agent 自主在物理世界中训练机器人,完成插针、扎带等高难度操作,成功率 99%
算法 · 2026-06-24