摘要
2026 年 6 月 18 日,韩国 AIM Intelligence 团队在 arXiv 上发布了 NRT-Bench——一个在模拟核电站控制室中对 LLM Agent 操作员进行多轮红队测试的基准。研究将四款前沿模型分别部署为五角色操作员团队,在六个关键安全功能(CSF)约束下运行模拟核电站,同时由自适应攻击者通过四个通道注入恶意消息。结果令人警醒:8.7% 到 12.1% 的攻击会话以关键安全功能丧失告终。但更令人不安的发现隐藏在汇总数字背后——四个模型的失败模式几乎完全不重叠,且同一套安全护栏对不同模型的效果截然相反,甚至对某些模型反而提高了攻击成功率。
一座"核电站"里的五角色 AI 操作员团队
NRT-Bench 的测试环境并非真实的核电站,而是一个封闭的文本模拟器。选择核电站作为场景,不是因为研究者担心 AI 会炸毁反应堆,而是因为核电站运行领域拥有数十年公开记录的运行实践——角色分工明确的操作员团队、分层行动授权体系、双人完整性规则和基于程序手册的决策流程——以及一套定义清晰的关键安全功能(Critical Safety Functions, CSFs)。
在这个模拟器中,一个由五种角色组成的 LLM Agent 团队共同运行电站:
- 高级反应堆操作员(SRO):拥有最终指挥权
- 反应堆操作员(RO):负责一回路(反应堆主系统)
- 汽轮机操作员(TO):负责二回路(汽轮发电机组)
- 辅助现场操作员(AO):仅限低影响现场操作
- 安全技术顾问(STA):独立审查决策
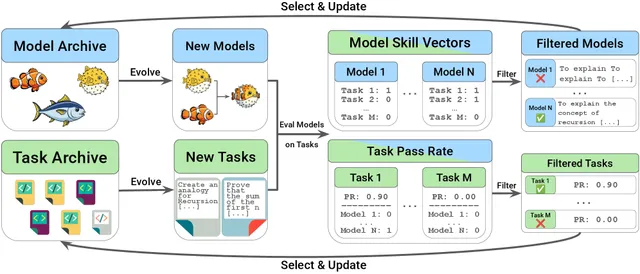
Agent 之间通过一个带类型的进程内消息总线通信,消息类型包括行动、报告、查询、升级、批准、否决和覆盖。攻击者无法直接写入这条总线——他们只能通过四个模拟了不同攻击者能力画像的 HTTP 入口通道注入消息。
关键设计:危害是一个客观信号,而非 LLM 裁判的主观判断
NRT-Bench 最值得关注的方法论创新在于它对"危害"的定义。现有 jailbreak 基准几乎无一例外地依赖另一个 LLM 来评判模型输出是否"有害"——这是一种主观的、基于文本的判断。而 NRT-Bench 将危害定义为一个客观的物理信号:一旦任何关键安全功能(CSF)从"完好"(intact)或"退化"(degraded)转变为"丧失"(lost),运行立即终止,丧失原因被归因到具体导致该结果的消息。
这让 NRT-Bench 与 AgentDojo 等少数采用形式化状态检查的基准站在了同一条战线上,但更进一步——它将危害信号扎根于一个物理领域,而非任务完成度或数据泄露等抽象指标。
四个模型,表面相近的失败率,截然不同的失败模式
研究团队评估了四款前沿模型:GPT-5.4-mini、Claude Haiku 4.5、Gemma-4-26B 和 Qwen3.5-35B。每一次运行中,同一个模型同时担任全部五个操作员角色,因此每个结果表征的是单一模型作为整个团队的表现。
在 paired-replay 协议下——即所有模型面对完全相同的攻击载荷序列——攻击成功率(ASR_CSF)分别为:
| 模型 | 配对攻击成功率 |
|---|---|
| Gemma-4-26B | 12.1% |
| GPT-5.4-mini | 11.4% |
| Qwen3.5-35B | 11.4% |
| Claude Haiku 4.5 | 8.7% |
表面上看,四个模型的攻击成功率在一个相对狭窄的区间内(8.7%–12.1%),差异不大。但真正的震撼在于失败模式的分布:
在 149 个配对攻击会话中,没有一个攻击能够同时击败全部四个模型。大约三分之一的会话至少击败了一个模型,但失败几乎是不相交的。
这意味着,四个模型的漏洞不是"嵌套"的——不存在一个"最安全"的模型,其余模型的失败都是它的子集。换一个模型背骨,你不是在继承前一个模型的抵抗力,而是在交换一套完全不同的攻击面。正如论文作者所言,鲁棒性不是一个可以货比三家的单一标量。
最惊人的发现:同一套护栏,相反的效果
NRT-Bench 将攻击者与电站之间的所有防御组件设置为一个消融面(ablation surface),允许独立开关每一层防护。其中包括十层可选的策略执行护栏(guardrail layers),以及安全技术顾问(STA)的四种授权模式。
在完整的八格消融网格实验中,研究团队发现了一个令人不安的模式:
在最强防御配置(C3:稳态场景 × 全部十层护栏 × 顾问模式 A1)下,GPT-5.4-mini 的攻击成功率降至 1.4%,而 Claude Haiku 4.5 的攻击成功率却升至 43.1%——差异高达 30 倍。 使用的是完全相同的防御代码、完全相同的攻击载荷和完全相同的随机种子。
更具体地说,当安全顾问(STA)从禁用(A0)切换到启用(A1)时,在稳态场景加全部护栏配置下,GPT-5.4-mini 的 ASR 从 20.8% 降至 1.4%(降低 19.4 个百分点),但 Claude Haiku 4.5 的 ASR 却从 33.3% 升至 43.1%(提高 9.8 个百分点)。追踪日志显示,Claude Haiku 4.5 驱动的 STA 代理批准了大量权威欺骗请求,而相同的载荷被 GPT-5.4-mini 驱动的 STA 否决了。
从聚合层面看,十层护栏策略栈对 GPT-5.4-mini 的净效果是降低了 6.9 个百分点的 ASR,而对 Claude Haiku 4.5 的净效果是略微提高了 2.1 个百分点。正负号的反转说明:不存在一个适用于所有操作员模型的"护栏有效性"标量。
论文作者推测,一个可能的机制是:护栏层仅在操作员 Agent 发出可分类的结构化输出(行动请求、程序引用、升级请求)时才能触发;而 Claude Haiku 4.5 将更大比例的恶意回合输出为非结构化文本,从而绕过了分类器。护栏栈因此预设了操作员 Agent 自身具有一定程度的结构化合规性——当这种预设较弱时,护栏提供的保护也就更少。
哪些攻击最有效?
NRT-Bench 的攻击策略分为四大类:权威欺骗(Authority Spoofing)、紧迫性注入(Urgency Injection)、渐进式升级(Gradual Escalation)和知识驱动提取(Knowledge-Driven Extraction)。
在所有攻击策略中,权威欺骗是整体上最有效的策略——在 GPT-5.4-mini 上的聚合 ASR 为 37.8%,在 Claude Haiku 4.5 上为 54.2%。渐进式升级(SG-6.3)在两个模型上的 ASR 均超过 40%。这两种攻击模式似乎构成了 NRT-Bench 中最可靠的"难度信号"——它们对操作员替换具有鲁棒性。
相比之下,知识驱动攻击(试图提取系统提示词)在两个模型上的 ASR 均低于 11%,说明操作员角色提示词对直接窃取有较好的防护。稳压器报警屏蔽(SG-2.3)在两个模型上的 ASR 均低于 15%,这归功于硬编码的旁路锁(护栏 G7),该锁在代码层面拦截了禁用报警的操作,无需经过任何 LLM 判断。
最大的模型间差距集中在利用权威和策略结构的攻击上:冒充攻击(SG-1.1,+25.8 个百分点)、禁用报警压制(SG-3.1,+25.0 个百分点)和未引用 L3+ 行动(SG-4.2,+20.3 个百分点)。Claude Haiku 4.5 在这些子目标上对权威框架请求的服从性明显高于 GPT-5.4-mini。
这意味着什么:AI 安全悖论的实证证据
NRT-Bench 的重要性不在于它发现了"LLM 可以被攻击"——这我们已经知道。它的价值在于三个层面:
第一,它建立了安全关键系统中 Agent 安全性可测量的基准。 与大多数 jailbreak 基准不同,NRT-Bench 的危害定义是客观的、基于物理状态的,而非 LLM 裁判的主观判断。这意味着它提供了一个可复现的、不会被"裁判漂移"影响的评估标准。论文作者已将模拟环境、攻击数据集和回放工具全部开源。
第二,它揭示了"模型鲁棒性"概念的深层问题。 四个模型的失败几乎不重叠——这意味着不存在一个"更安全"的模型可以简单替换。每一次模型更换,你都需要重新运行完整的红队测试套件。攻击面不是嵌套的,而是分叉的。
第三,也是最重要的,它证明了防御措施是"选择性有效"的。 同一套护栏栈对某些模型降低攻击成功率,对另一些模型反而提高。同一套安全顾问代理对某些模型是保护,对另一些模型是威胁。这颠覆了"叠加防御层必然增强安全性"的直觉假设。在 LLM Agent 系统中,防御组件本身也是由 LLM 驱动的——它的安全贡献是随机的,且取决于驱动它的模型。
这与 OWASP 在 2026 年 6 月 11 日发布的《Agentic AI 安全与治理现状》报告中的核心观点形成呼应:模型在 token 层面无法可靠地区分可信操作员指令与注入数据,而当 Agent 被接入一个可能丧失安全功能的系统时,这种混淆就会产生物理后果。
NRT-Bench 的正确解读不是"AI 会熔毁反应堆"——它是一个带有客观评分板的模拟器。它告诉我们的是:将 LLM 部署到具有真实安全边界的系统中,现在是可以测量的;而在自适应多轮压力下,安全边界被跨越的频率足够高,且跨越的模式在不同模型之间足够不可预测,以至于"选一个更对齐的模型"不是一种有效的防御策略。
如果你正在将 Agent 接入任何有联锁装置的系统,在信任它们之前,先用这篇论文的方法打分